|
|
|
Diagnosis菜单Diagnosis(诊断)下拉菜单建议一个逐步的过程来调查您的分析结果。
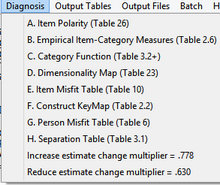
A. Item Polarity:检查所有项目在潜在变量上的方向是否一致,同Table 26。检查所有项目是否具有正相关。 使用 IREFER= 和 IVALUE= 将所有项目指向同一方向,或使用 KEY1= 更正多选键错误。 IDFILE= 删除(暂时)不合作的项目。 B. Empirical Item-Category Measures: 检查所有项目的所有类别是否在同一方向上对齐,与Table 2.6 相同。 对于多项选择题,请参阅表 2 中的 MCQ。 检查正确答案和对应于变量“更多”的更高类别值是否在右侧。 C. Category Function: 检查所有分类是否按预期运行,与Table 3.2 开始相同。 检查类别的“平均度量”是否提前,并且没有类别特别嘈杂。 使用 IREFER= 和 IVALUE= 折叠或删除不一致的类别。 使用 ISGROUPS= 来识别类别功能。 如果需要更多详细信息,请查看项目表的选项/干扰分析。 D. Dimensionality: 检查所有项目是否共享相同的维度,与Table 23 相同。这通过执行观察残差的主成分/对比分解来识别数据中的子结构,“二级维度”。 如果有较大的子结构,那么将数据分成两个测量仪器可能更明智。 E. Item Misfit:检查项目是否配合测量,同Table 10。是否有不当项目? 寻找大的均方,并在选项/干扰列表中寻找相互矛盾的响应。 F. Construct KeyMap: 检查项目层次结构是否符合预期(构造有效性),与Table 2.2 相同。 这会将项目、响应类别和您的样本定位在一张图片中。 您的项目度量层次结构有意义吗? 您样本中的典型人物是什么意思? G. Person Misfit:检查人员是否配合测量,同Table 6。是否有行为不端的人员? 查找较大的均方,并查看“最意外的响应”子表中的意外观察结果。 H. Separation :检查项目区分不同水平的人表现(“测试”可靠性),与表 3.1 相同。 此外,人们能够区分项目校准的差异。 Increase estimate change multiplier =Reduce estimate change multiplier = 通常的估计变化乘数 ESTMULT= 是 0.7。 增加此值会增加每次迭代中更改的大小。 如果 ESTMULT= 太大,则估计会发散,从而使最大残差变得更大。
|
|
|
| 站点地图|隐私政策|加入我们 |
Copyright ©2022 上海卡贝信息技术有限公司 All rights reserved. |